A couple of years ago, I asked for a recommendation for a “personal CRM” – a client-relationship management tool intended for individual use. As it turns out, I wasn’ttheonlyone asking, and a solution still hasn’t emerged despite outsized interest from the very designers and developers who should be well-poised to create it. Why?
I’ve come to believe that this is because “personal CRM” means something a bit different to each person who asks for it. To my friend Shane, it’d be akin to a proactive virtual assistant, skewing towards the “magical” end of the spectrum. I myself have envisioned a few different products, all which I’ve lazily described using this umbrella term: one for letting me know when I haven’t seen a certain friend in a while, another for applying “tags” to former coworkers, etc. During my current job search, I’ve needed different tools at different times: one centered around colleague outreach to start, but another for tracking interview processes as the’ve continued to progress.
When faced with a moving target and only concerned with meeting one’s own individual needs, we don’t need an “app” or a “product” per se. A document can be structured in a way that meets today’s needs, with the flexibility to easily evolve as requirements change. My “personal CRM” is currently a spreadsheet – I could’ve built a version using Excel or Google Sheets, but I chose Airtable because it stores data in a more structured, database-like format. This lets me build more powerful, customized views on top of my data.
A database. With custom UI sitting on top of it.
This is “an app,” my friends.
Documents vs. apps
From this perspective, Airtable isn’t necessarily a product in-and-of-itself, but a platform that empowers you to build your own products – and it’s far from the only one. Coda, Notion, Quip, Clay, and Actiondesk are also similar in that they’re democratizing software development under the familiar guise of “collaborating on documents.1” But their document-sheen is only skin-deep:
A creative palette of app-like functionality that you can mix and match
Build something as unique as your team
We took the quintessential parts of apps and turned them into building blocks for your docs
Our goal is to make it much easier to build software
Forget the back and forth with your tech teams. Build powerful automations yourself
Zapier, IFTTT, and Apple’s Shortcuts focus more on integrations and less on data storage and UI, but they’re also key parts of this emerging space – not all software needs a visual user interface2. Even Slack – an enterprise chat application on the face of it, has ingrained itself in no small part due to its integrations platform, allowing teams to build mini-products and workflows that suit their own specific needs.
These aren’t necessarily new ideas – Excel macros and Google Sheets scripts3 are less holistic solutions that nonetheless strive to answer the same question: how can we lower the software development barrier to entry?
Apps for small audiences
Part of what made my own CRM so easy to build was the assumption that I’m going to be the only one who ever uses it. Turning it into a consumer-facing product would be a much taller task, but there’s still a ton of value to be captured by software that’s only used by individuals or teams internal to a company.
We’ll start designing apps for small audiences, not big. Companies will run on their own apps, hundreds of them, tailor-made for every team, project, and meeting. In this world, there’ll be no such thing as an edge case. All the previously underserved teams and individuals will get a perfect-fitting solution without needing to beg an engineer.
Internal applications also have lower user experience expectations than their consumer-facing counterparts, and are simpler for users to authenticate with. And by providing value, they don’t require business models of their own to justify the upfront development cost.
Another approach: instead of using one app-building “platform”, what if the makers of the future study the skills necessary to combine existing applications together themselves, instead of studying computer science fundamentals? MakerPad is one such example of a program and community attempting to educate in this regard:
✔️ Airbnb-clone marketplace w/ no-code
- Pages auto-generated from CMS - Book via @airtable - @zapier updates the row - @stripe invoice sent - Once paid, the row is 'confirmed' in calendar on site
While such an approach may not suffice in perpetuity, it could mean the difference between bootstrapping yourself to profitability and prematurely taking venture capital in order to hire an engineering team.
What happens to software developers?
As a software developer, should I find this concerning? I admittedly do not, and think that Steven Sinofsky succinctly articulates why by providing some key historical context:
One thing to consider is that no-code tools arise when there's an implied consensus that platforms are stable. One takeaway is that the web, iOS, android are not going to change a ton in the foreseeable future so tools can abstract across them.
This is all a point in time thing. The longer term challenge is that software built this way may/may not be more difficult to adapt when the platforms do change.
Platform makers put some effort into moving ‘native’ apps to new eras, but abstracted apps get stuck.
The layers of abstraction that software developers work on top of are continually changing, but there will always be problems to solve despite moving higher and higher up the stack. Most of the platforms covered in this essay already integrate with the popular services of the moment, but developers will always have an advantage insofar as being able to build their own integrations to augment whatever a platform vendor happens to provide out-of-the-box. Understanding databases makes it easier to create a complex Airtable sheet, just as being familiar with loops and conditionals makes you better equipped to craft a complicated workflow in the Shortcuts app. The line between what is and isn’t “programming” really starts to blur.
Similarly, there has always been a gradient between what can be done without code and when you’ll eventually hit a wall with that kind of approach. Adobe Dreamweaver never quite obviated writing your own custom HTML, did it? I don’t personally foresee this ceasing to be the case.
But traditional software development being long for this world isn’t an excuse not to keep up with the changing times. Adobe’s new XD/Airtable integration might be marketed as a prototyping tool today, but how long will it be until those prototypes are good enough for a single designer to ship as production software?
Coda goes so far as to intelligently translate traditional desktop documents into common mobile app paradigms. A section in a document becomes a tab in an app’s navigation, and a select box with multiple states can be edited using a native swipe-gesture. ↩
Especially as voice control and home automation continue to increase in prominence. ↩
Instances of this same user model type can be vended by multiple routes, e.g.:
/me – A route that returns the currently authenticated user
/friends - A route that returns the current user’s friends
RESTful APIs aren’t inherently type-safe, so a frontend developer will generally learn that these routes both return objects of the same User type by looking at the API documentation (and hoping that it’s accurate1), or by eyeballing the HTTP traffic itself.
After realizing this, a type definition like the following can be manually added to your client-side application, instances of which you can populate when parsing response bodies from either of these two routes:
This shared, canonical User model can be used by any part of the frontend application that needs any subset of a user’s attributes. You can easily cache these User instances in your client-side key-value store or relational database.
Suppose that your application includes the following capabilities (and is continuing to grow in complexity):
Rendering user profiles (requires all user properties)
Viewing a list of friends (requires user names and avatars only)
Showing the current user’s avatar in the navigation (requires avatar only)
Your server will initially return the same user payload from all of these features’ routes, but this won’t scale particularly well. A model with a large number of properties2 will be necessary to render a full profile, but problematic when rendering a long list of users’ names and avatars. It’s unnecessary at best and a performance bottleneck at worst3 to serialize a full user when most of its properties are simply going to be ignored.
Perhaps your API developer changes your server to return only a subset of user properties from the /friends route. This is followed by a change to the API documentation and a hope that your frontend engineer notices, at which point they’ll add a new type to the client-side codebase. Perhaps this new type looks something like:
Keep track of which routes vend User instances vs. SimpleUser instances, when processing HTTP responses
Have its caching logic updated to support both of these different types
User vs. SimpleUser is admittedly a coarse and superficial distinction. If we add a third flavor to the mix, what would we reasonably name it?
Instead of SimpleUser, we could instead call this new type FriendListUser, named after the feature that it powers. Having separate user models for each use case is a more scalable approach – we could end up with quite a few different versions, whose names all accurately convey intention better than “simple” does:
FriendListUser
EditAccountUser
ProfileUser
LoggedOutProfileUser
The risk here is that we’re likely to incur a lot of overhead in terms of keeping track of which routes vend which models, and how to make sense of all of these different variants when modeling our frontend persistence layer.
Reducing this overhead by more tightly coupling our client-side type definitions to our API specification would be a big step in the right direction. GraphQL is one tool for facilitating exactly this.
GraphQL
There’s a lot to like about GraphQL – if you’re looking for a comprehensive overview, I’d recommend checking out the official documentation.
One advantage over traditional RESTful interfaces is that GraphQL servers vend strongly-typed schemas. These schemas can be programmatically introspected, making your APIs self-documenting by default4. But this is an essay about client-side models, not avoiding stale documentation.
With higher model specificity comes higher clarity and efficiency, the primary downside being the additional work involved to maintain a larger number of models. Let’s dig deeper into how code generation can mitigate this downside.
By introspecting both:
Our backend API’s strongly-typed schema
Our frontend app’s data needs
We can easily generate bespoke client-side models for each individual use case.
First, we must understand how GraphQL queries work. In a traditional RESTful API server, the same routes always vend the same models. Let’s say that our GraphQL server exposes the following two queries:
me: User
friends: [User]
While both queries expose the same server-side User model, the client specifies the subset of properties that it’s interested in, and only these properties are returned. Our frontend might make the following query:
me {
firstName
lastName
location {
city
state
}
avatar {
large
}
}
The server will only return the properties specified above, even though the server-side user model contains far more properties than were actually requested.
Similarly, this query will return a different subset:
Code generation tools can introspect these client-side queries, plus the API schema definition, in order to:
Ensure that only valid properties are being queried for (even directly within your IDE, validating your API calls at compile-time)
Generate client-side models specific to each distinct query
In this case, the generated models would look as follows:
// Generated to support our `me` queryinterfaceUser_me{firstName:string;lastName:string;location:User_me_location;avatar:User_me_avatar;}interfaceUser_me_location{city:string;state:string;}interfaceUser_me_avatar{large:string;}// Generated to support our `friends` queryinterfaceUser_friends{firstName:string;lastName:string;avatar:User_friends_avatar;}interfaceUser_friends_avatar{thumbnail:string;}
Each of our app’s components can now be supplied with a model perfectly suited to their needs, without the overhead of maintaining all of these type variations ourselves.
Trees of components, trees of queries
User interface libraries like React and UIKit allow encapsulated components to be composed together into a complex hierarchy. Each component has its own state requirements that the other components ideally needn’t concern themselves with.
This is at odds with traditional RESTful API development, where a single route will often return a large swath of data used to populate whole branch of the component tree, rather than just an individual node.
GraphQL query fragments better facilitate the colocation of components and their data requirements:
This results in a “query hierarchy” that much better aligns with our component hierarchy.
Just as a UI rendering layer will walk the component tree in order to lay out our full interface hierarchy, a GraphQL networking layer will aggregate queries and fragments into a single, consolidated payload to be requested from our server.
Heterogenous caching made simple
GraphQL is a high-level query language; while you can use it to query a GraphQL server, client-side libraries such as Apollo and Relay can act as abstraction layers on top of both the network as well as an optional local cache5.
(Additionally, Apollo and Relay both also handle the code generation and query fragment unification outlined in the sections above 💫)
Traditional client-server applications often end up with logic that looks as follows:
// Check if we have a certain user in our cacheifletuser=db.query("SELECT FROM users WHERE id = \(id)").first{callback(user)}else{// Fetch from the network insteadAPI.request("/users?id=\(id)").onSuccess{responseincallback(response.user)}}
In this case, we’re querying for the same user via two different mechanisms: SQL against our local database and a URL-encoded query string against our remote server.
Apollo and similar libraries allow us to more declaratively specify the data that we need in one unified way. This level of abstraction lets us delegate the heavy-lifting – checking whether our request can be fulfilled purely from cache, and augmenting with additional remote data if not.
To continue our example: if you first made a friends query, your cached users would only contain firstName, lastName, and avatar.thumbnail properties. A subsequent me query for one of those same users would hit the server in order to “fill in” the additional properties – location and avatar.large. From this point forward, subsequent friends or me queries could avoid the network roundtrip altogether5.
As long as two user models have the same unique identifier, it doesn’t matter which subset of their properties were fetched in which order. Apollo will take care of normalizing them for us.
Sound magical? It certainly can be, for better or for worse. Like all high levels of abstraction, it’s amazing when it’s working and infuriating when it isn’t.
But such is the promise of GraphQL; the sky is the limit for tooling when a typed schema definition is the foundation being built upon. Tooling of this nature can make a premise that would’ve otherwise seemed prohibitively unwieldy – having a distinct client-side model type for every slight use case variation – not only achievable, but ideal.
More likely if it’s generated using something like Swagger, less likely if your API engineer is manually doing their best to keep it up to date. ↩
Just imagine how many properties a Facebook user is comprised of, for example. ↩
Not to mention, disrespectful of your users’ time and cellular data plans. ↩
Tools like GraphiQL allow you to see exactly which server-side models are vended by each of your GraphQL queries. ↩
Last year I only read two books. I’m disappointed by that, and my goal this year is to read somewhere closer to ten, alternating between fiction and non-fiction. To hold myself accountable, I will try to write a little about each, starting with this one.
I only ended up reading five books in 2013, but read seven in 2017 and seventeen in 20181. At risk of jinxing it, I think it’s safe to say that – many years later – I’ve finally adopted a real reading habit for the first time as an adult.
Habits are obviously quite personal, and there’s no shortage of advice out there on how to make one out of reading in particular2. Here are the few keys to my own personal success on this front that I hope may prove helpful to you as well.
Committing to a platform
I spent far too long being really indecisive as to whether I should invest in Apple or Amazon:
Sadly, I’m positive that I’d read a lot more if I wasn’t paralyzed by indecision over iBooks vs. Kindle lock-in.
I eventually committed to Amazon due to Goodreads, local library rentals, and e-ink Kindle devices (more on all of these later). Most important was to simply make a decision, however; I think I’d be doing just fine had I chose Apple instead.
I still prefer Apple for programming books because I find the Apple Books software for macOS to be far superior to Kindle’s desktop web experience, but these are a small percentage of the books that I read overall. I’ve been very happy with Kindle as my default for everything else.
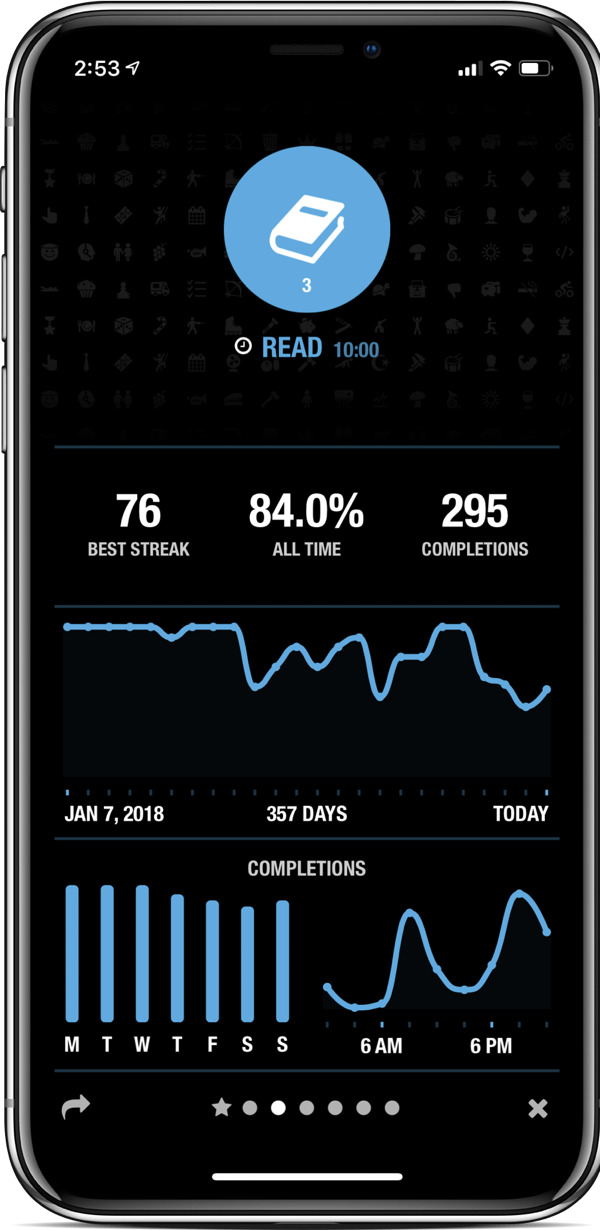
Keeping a streak
If you’re the type of person who finds streaks to be motivational, keeping track of a streak is an easy way to make sure that you’re spending at least a few minutes reading each day. Just five or ten minutes each day is a great place to start; those minutes really do add up, but perhaps more importantly, a streak helps ingrain the habit of dipping into your book during your commute or while waiting in line at the grocery store. Or really, anytime when you might otherwise default to scrolling through Twitter or Instagram.
I highly recommend Streaks for iOS. It even has built-in timers for letting you know when you’ve finished reading for the desired increment.
Allowing myself to take breaks from books
There are some days where I simply don’t want to read a book, but that doesn’t mean I can’t read something else of value. The goal here was to instill a reading habit, not necessarily a book habit.
Maybe I just finished my last book and haven’t decided which my next one will be, or maybe there’s a lot going on in the news that I’d like to catch up on. I use Instapaper to save articles of all different kinds to read at a later date, and on days where I choose to spend at least ten minutes reading these instead of a book, I’m happy to count that against the streak as well.
Using an e-ink Kindle
I resisted getting a dedicated Kindle device until December 2016, primarily because I really don’t mind reading on iOS. I’ve read entire books on iPhones without issue.
I eventually moved to a Kindle as my primary reading device not because I prefer e-ink screens to LCD or OLED, but because I am very bad at avoiding distractions. My Kindle doesn’t have notifications, a web browser, or a Twitter client. I can do nothing but read on it, so read without interruption I do.
Modern Kindles also have the benefit of being quite light and small. I expected to only bring mine along when carrying a bag, but it fits pretty easily in many of my jacket pockets. As such, I’ve carried it far more often than I would’ve originally guessed.
Reading wherever, whenever
Despite having really grown to like my Kindle, it’s only with me a fraction of the time compared to my iPhone. Like with cameras, the best book is the one that’s with you. Kindle sync means that your book is always with you as long as your phone is, even if your primary reading device is not. And as mentioned, I’m definitely not above reading books on my phone.
There are plenty of times where I most certainly do not want to carry anything more than my phone – specifically in the summer – but this doesn’t mean that there can’t still be any number of planned or unplanned reading opportunities along the way.
Drowning out the noise
In the spirit of reading wherever and whenever, it’s often helpful to have something to help you drown out the background noise of your neighborhood coffee shop, or the New York City subway. I’ve been using Brain.fm almost exclusively for the past year but have also used Noizio a lot in the past. They’re both really good at what they do.
Putting a book cover on my lock screen
Whenever I start a new book, I put the book’s cover on my iPhone lock screen3. It’s not exactly subtle, but I benefit from the constant reminder that I could be reading my book whenever I’m tempted to use my phone for something less beneficial.
“Bonnie made a joke now as she served him his martini. She made the same joke every time she served anybody a martini. “Breakfast of Champions,” she said.”
If you’d like to make your own lock screen wallpaper, here’s the Sketch template that I use.
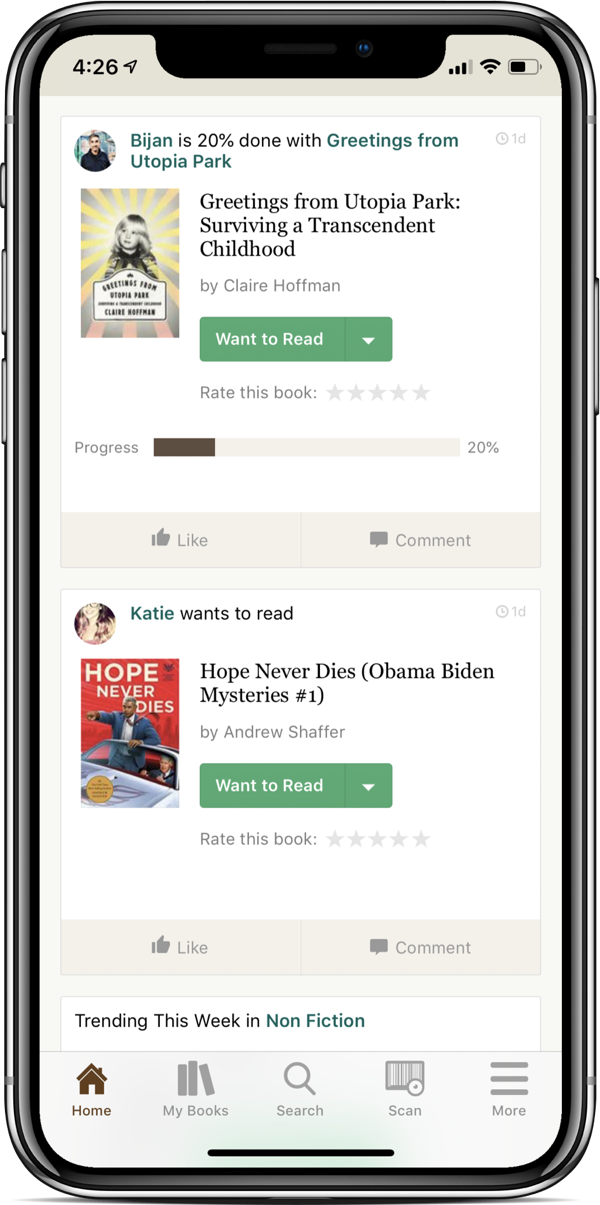
Using Goodreads
Goodreads is a social network for keeping track of what you and your friends are reading and want to read in the future. It’s owned by Amazon, and as such is able to automatically track any books that you’ve read using Kindle apps or devices.
Having Goodreads friends like Katie is one of the best ways to keep inspired and motivated.
While the website and iOS app could both use a bit of user interface love, I’ve found it to be a huge help in keeping a reading habit by providing:
A steady influx of new book suggestions, specifically from those who share your tastes
Guilt, if you’ve lapsed a bit yet see all of the books that your friends keep finishing
Renting from the library
Did you know that not only can you borrow physical books for free from your local library, but ebooks as well? More surprising, perhaps: Libby, the iOS app used to do so, is actually quite nice.
Libby even supports multiple accounts, if you’re lucky enough to have more than one in your area.
The selection isn’t perfect, but I’ve been able to find a lot of books on my reading lists at either the New York or Brooklyn Public Libraries4. You may need to wait a few weeks for popular books to become available, but you can put them on hold such that they’re automatically rented once they are. Once rented, you can keep the book for up to 21 days (which I’ve found can serve as a helpful forcing function to make sure you’re moving through it with haste).
These are just a few tactics, but they’ve worked well for me over the past year and I expect will continue in years to come. I still think there’s room for improvement5, but the first step to improving a habit is to have said habit in the first place. As of 2018, I can finally say that I do.
I didn’t really keep track from 2014 through 2016. Day One and Goodreads indicate that I read at least three in 2014, at least three in 2015, and at least two in 2016. Nothing to brag about. ↩
A couple of favorites: this one from Rick Webb (my former Tumblr colleague and a far more prolific reader than I am ever likely to be), and this one from Paul Stamatiou. ↩
I wish I could take credit for this, but I got the idea from Twitter at some point and can’t find the source for the life of me. Apologies! ↩
Your mileage may vary depending on your local library, of course. ↩